
Products
Solutions
Published
27 November 2025
Written by Elliott Lee-Hearn
Some engineers struggle with thermal design, some with EMC, some with datasheets.
Elliott struggles with names and faces.
Inside the ipXchange office we’ve got 10+ human staff members and, more importantly, 2 Labradoodles, Kizzy and Wilbur. They’re adorable, they roam the office freely, and for Elliott… they are completely indistinguishable.

Rather than improve his memory like a normal human, he decided to take the engineering route. He would fix the problem with machine learning. The plan? Train a computer vision model that could look at a dog and tell him whether it was Kizzy, Wilbur, or neither.
Curating the Dataset
A good classification model needs a large, well-constructed dataset. The first step was to define 3 classes:
- Kizzy
- Wilbur
- Neither (basically: everything that is not those two dogs)
That last class was important. For a model to correctly identify a specific dog, it must also reliably recognise what isn’t that dog. So Elliott filled it with:
- other dogs
- photos of the entire ipXchange office
- London street shots
- his garden
- stairs
- basically anything that wasn’t two Labradoodles
As much as you need to teach the model what a dog is, you have to teach it what a dog isn't...
Training the Model in Edge Impulse
Now for the fun part: turning the images into a working machine learning model. (follow along with the video if you like!
Uploading Data
Elliott created a new Edge Impulse project, named it, uploaded his dataset, and labelled it properly. The platform automatically split his data into training and testing, in a ratio that can be changed later.
Creating the Impulse
An impulse is a machine learning pipeline, and in a classification example, it will intake labelled images of any size and file type, resize them to 96×96 pixels, pre-process them, extract features, feed them through a transfer learning block, and output a quantised machine learning model, fit to run on your specific hardware.
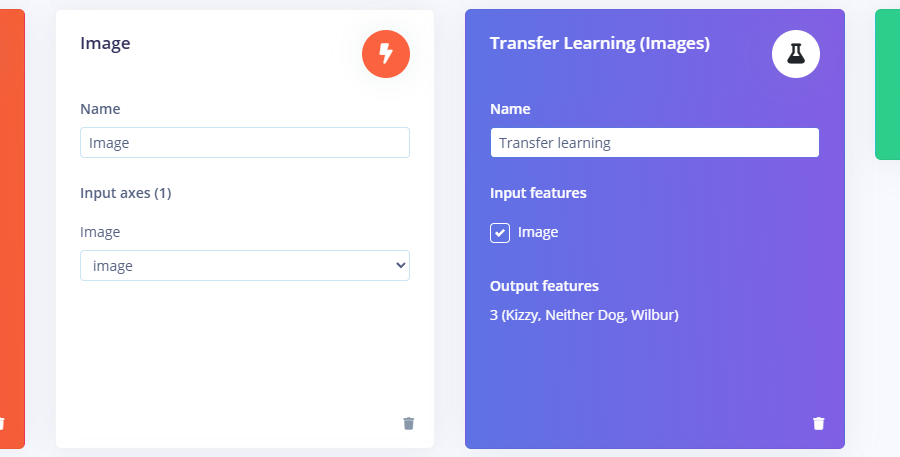
Fine-Tuning the Transfer Learning Block
Since the chosen deployment target was an Arduino Nicla Vision, Elliott picked a lightweight variant: MobileNetV1, 96×96, with a 0.1 width multiplier. He increased the number of training cycles and learning rate, enabled data augmentation, and pressed train.
After many training iterations with low accuracy, it was revealed that the dataset used to train the model needed improvement – too many hard images were included for the small dataset. Images like these are important for putting a classification model to the test, but for a small dataset like the one used in the ipXchange design video, the model learnt strange patterns. Images like this…

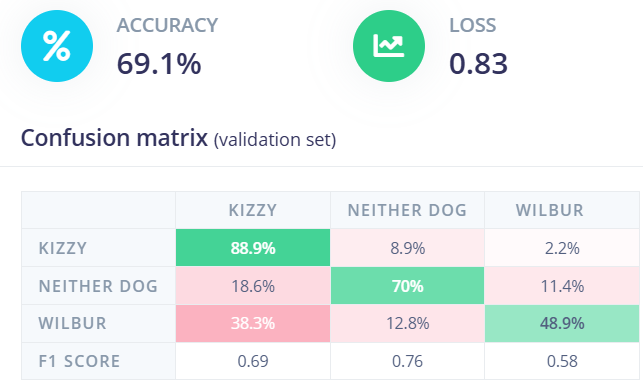
These images were removed, and the final training accuracy, loss, and confusion matrix can be viewed below. The confusion matrix can be used to determine the models theoretical performance. Rows show the actual class, and columns show the predicted label. For the top right row, it reads: When an image of Kizzy is classified, 2.2% of the time it is incorrectly classified as Wilbur.
Deploying the Model to an Arduino Nicla Vision
The Arduino Nicla Vision is a compact, ultra-low-power embedded vision module that combines a camera, microcontroller, and onboard AI acceleration to run real-time machine-learning models directly on the edge. It is supported by Edge Impulse, alongside a broad selection of other processors and development boards.
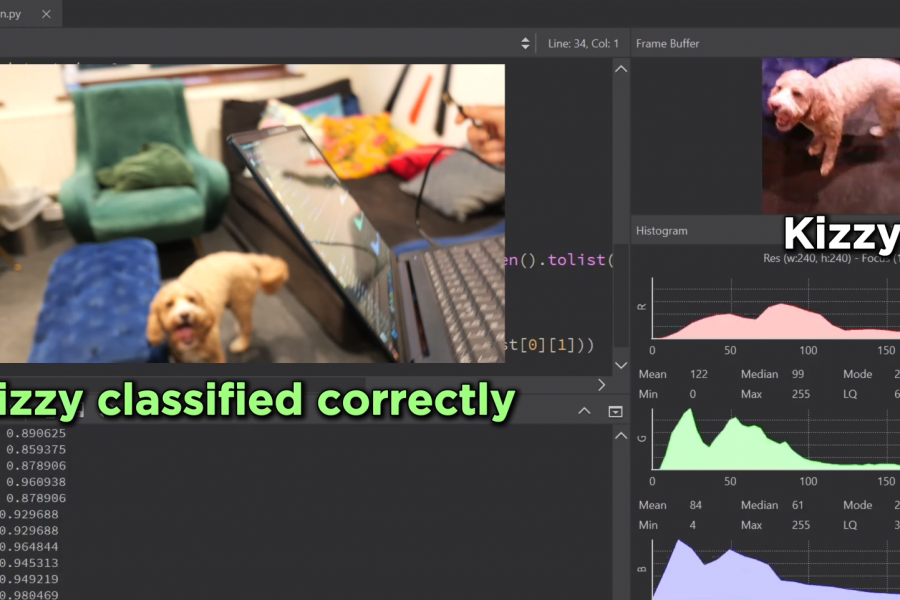
By navigating to the ‘deployment’ section, Elliott exported a quantised (int8) model, built for use with OpenMV firmware. OpenMV was used with the Nicla Vision because it provides a lightweight, Python-based environment that abstracts away the complexity of running vision models on embedded hardware.
Instead of writing low-level firmware, managing camera drivers, or handling memory manually, OpenMV packages everything into a simple workflow where you can load the Edge Impulse–generated script, flash the board, and immediately run inference. It turns the Nicla Vision into a plug-and-play computer-vision device, giving you live camera access, serial output, debugging tools, and model execution all in one place.
Improvements for Next Time
The model was able to classify Kizzy and Wilbur in most cases, but in edge scenarios – like both dogs visible in the same frame, images where the dogs are obscured, and in low light, the model didn’t perform well. Elliott believes that this issue was caused by a lack of data, and diversity of that data. For a robust model, it’s important to use thousands of images, in different light levels, different backgrounds, different objects in the photos, taken from different angles, etc.
In the webinar on December 4th, 2025, Elliott is reattempting with a new classification example: mugs vs pens. Join him using this link, and you’re reading this after December 4th, you can watch the full recording here!
Machine Learning for Something Silly, and Something Serious
This whole project started as a joke about Elliott forgetting dog names, but it demonstrates something important: Edge AI isn’t just a research tool. It’s accessible. It’s practical. And it’s powerful even when used for fun.
Tools like Edge Impulse allow embedded engineers to:
- build gesture recognisers
- deploy audio classifiers
- identify objects in real time
- or, yes, create a dog classifier
All without needing a machine-learning degree!
Comments are closed.
Comments
No comments yet