




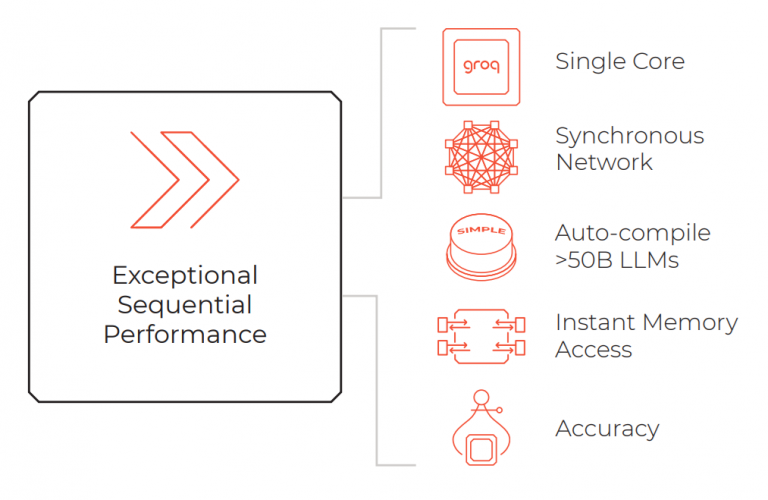
Groq’s LPU (Language Processing Unit) is a purpose-built AI inferencing device for lowest-latency processing at scale, i.e., when multiple units are used as part of a synchronous network. This is in contrast to the performance of GPUs, which does not scale linearly and results in declining application benefits for additional units in a system.
The simplicity of Groq’s single-core LPU architecture enables sequential processing workloads, such as those required for LLM (Large Language Model) AI, to run significantly faster, at higher efficiency, and with higher precision than currently available GPU architectures. It also offers instant memory access, reducing the time required to generate sequential inferences.
An example of an LPU-supplemented datacentre in action has shown Llama-2 70B running at over 300 tokens per second per user. In real-world scenarios, this enables ultra-low-latency AI chatbots that do not suffer from the ‘thinking time’ issue that makes a user aware that they are talking to an AI.
Groq enables developers access to this technology either with GroqCloud via API access or by building private datacentres with cards containing its LPUs. Fill out the form below to enter consultation with Groq for the best way to use this technology in your application and bring next-level LLM functionality to your latest designs.